So far we've seen how to write Python code to that loads and process Astro Pi CSV data files and how to filter the data for a specific date.
In this post we'll using some simple statistics functions to analyse each day in our data set to spot where something out of the ordinary happened.
To begin load up the date filter code and add a new import at the top (note you'll need to use Python 3.4 or later for this library module):.
import statistics
Now add these two new function definitions:
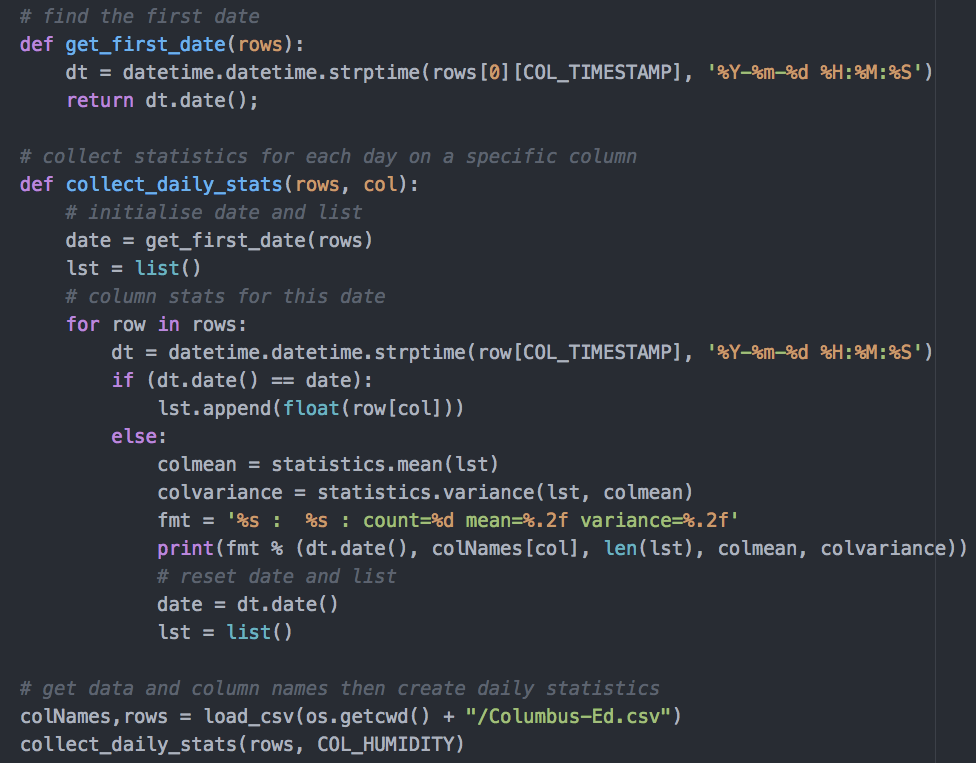
The get_first_date() function finds the first date in the date set. While the second collect_stats() calls this function before looping through all the rows to build date-specific data list for the specified column.
Then we call the statistics mean and variance statistical functions of our date-specific data collection. These values are then printed out.
Finally, in the main code area, we simply call the collect_daily_stats() function with our chosen column number.
As you can see from the output there was a big variance in the humidity data on 21st February 2016.
2016-02-17 humidity: count=4740 mean=45.41 variance=0.12
2016-02-18 humidity: count=8565 mean=45.54 variance=0.68
2016-02-19 humidity: count=8555 mean=45.22 variance=1.97
2016-02-20 humidity: count=8579 mean=44.90 variance=0.12
2016-02-21 humidity: count=8557 mean=49.07 variance=20.28
2016-02-22 humidity: count=8559 mean=47.65 variance=0.47
2016-02-23 humidity: count=8559 mean=47.12 variance=0.73
2016-02-24 humidity: count=8564 mean=47.34 variance=0.31
2016-02-25 humidity: count=8559 mean=46.86 variance=0.12
2016-02-26 humidity: count=8570 mean=46.49 variance=0.23
2016-02-27 humidity: count=8560 mean=45.73 variance=0.14
2016-02-28 humidity: count=8561 mean=45.71 variance=0.08
2016-02-29 humidity: count=8575 mean=45.02 variance=0.08
The Python statistics library model has many other functions, so have some fun experimenting with some other statistical techniques.
Start coding today with my Learn Python on the Raspberry Pi tutorial.